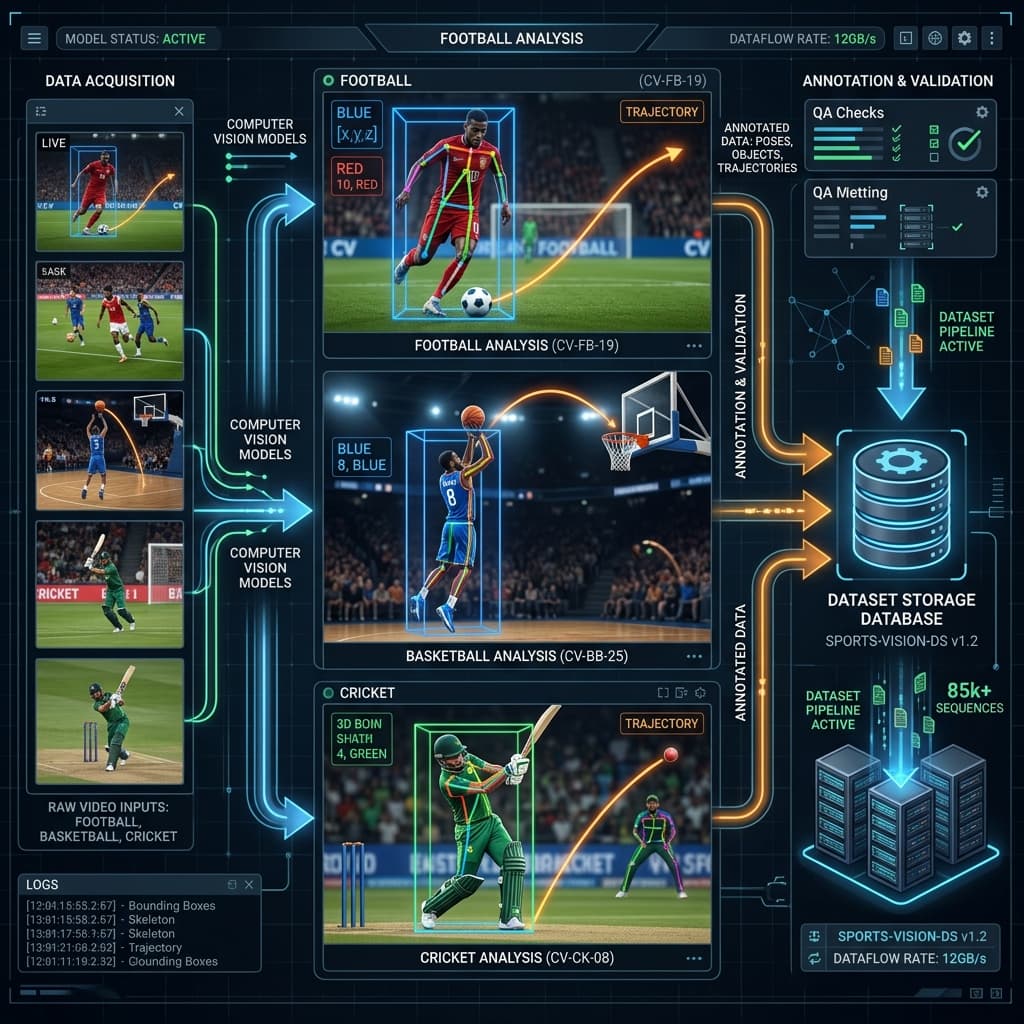
Building a sports computer vision model starts well before training begins. The decisions that determine whether your model performs in production — the schema, the annotation taxonomy, the QA process, the footage selection — are all made during dataset construction. Get them right and you have a model that generalises. Get them wrong and you have a model that passes benchmarks but breaks on real match footage.
This guide covers the six-step process for building a sports CV training dataset that actually trains the model you need.
 High-end technical visualization of the sports computer vision dataset annotation process, including bounding boxes, pose estimation, and temporal flow.
High-end technical visualization of the sports computer vision dataset annotation process, including bounding boxes, pose estimation, and temporal flow.
What is a sports computer vision training dataset?
A sports computer vision training dataset is a collection of annotated sports footage — labeled with bounding boxes, player IDs, skeletal keypoints, ball positions, event classifications or a combination — that a machine learning model learns from. It is the ground truth that defines the upper limit of what your model can understand about the sport.
A model cannot learn what it was never shown. If your training dataset contains inconsistent player IDs, wrong event labels or missing occlusion handling, your model learns those inconsistencies. No architecture choice, no training technique and no fine-tuning approach can compensate for a broken dataset.
The five types of sports CV training datasets
Sports computer vision covers several distinct model types, each requiring different annotation. Understanding which type you need determines everything downstream.
| Dataset type | What it trains | Primary annotation |
|---|---|---|
| Detection dataset | Finds players, ball, officials in a frame | Bounding boxes, class labels |
| Tracking dataset | Maintains identity across frames over time | Persistent IDs, occlusion flags, temporal sequences |
| Pose estimation dataset | Maps body keypoints per athlete per frame | 22-point skeletal keypoints, visibility states |
| Event recognition dataset | Classifies in-game actions with timestamps | Frame-accurate event labels, player ID links, outcomes |
| Multi-task dataset | Trains models that detect, track and classify simultaneously | Combined annotation across all types above |
Most production sports CV models eventually need multi-task data. But the schema for each task is different, and combining them without a clear design usually produces a dataset that is mediocre at all tasks rather than excellent at any one.
Step 1: Define your model objective precisely
The most common dataset mistake is starting annotation before the model objective is fully defined. "We need to track players" is not an objective. It is a category. The actual objective might be:
- Maintain player identity across a full 90-minute match sequence, including camera cuts and periods of full occlusion
- Classify every defensive assignment change in a basketball possession from a single broadcast camera
- Detect ball contact events in cricket with frame-accurate precision for DRS-grade trajectory analysis
- Estimate a bowler's release mechanics from a behind-the-wicket camera at 50fps
Each of these requires a completely different dataset. The first needs long temporal sequences with verified identity continuity. The second needs dense basketball event taxonomy and multi-player ID links. The third needs ball position labels at single-frame precision during fast motion. The fourth needs dense skeletal keypoints on a single athlete under specific camera conditions.
Before any footage is annotated, write down:
- What question does the model answer at inference time?
- What input does the model receive (video, frame, clip, multi-camera)?
- What output does it produce (bounding box, class label, trajectory, event type)?
- What is the performance threshold that makes the output usable in production?
The answers determine your annotation schema. Without them, you are annotating blind.
Step 2: Design your annotation schema before any labeling starts
A schema is the formal specification of everything your dataset contains: every label type, every attribute, every edge case decision and the output format the labels are delivered in.
A schema for a football event recognition dataset might specify:
- Event classes: pass, shot, tackle, interception, foul, corner, offside
- Event attributes: outcome (completed / incomplete), pressure level (under pressure / free), body part (right foot / left foot / head), zone of origin (defined court zones)
- Player ID links: which player IDs are involved as actor, recipient, and nearest defender
- Temporal labels: event start frame (defined as the last frame before foot/body contact with ball), event end frame (defined as the first frame when ball possession is clearly transferred or lost)
- Edge case rules: deflections that change event type, simultaneous fouls, events that span a camera cut
- Output format: JSON with frame references, player ID arrays and confidence values
Without this specification, different annotators answer edge case questions differently. Two annotators watching the same clip will disagree on whether the player was "under pressure" (which one is right?), when exactly the event started (frame 1,042 or 1,044?), and whether to label a deflected clearance as a pass or a clearance. For a model, that disagreement is noise. Enough noise removes the performance ceiling regardless of how many annotations you produce.
Schema design takes longer than annotators or project managers typically expect. It is not a morning's work. For a new sport or a new model objective, a complete schema requires multiple rounds of annotation, review and revision before it stabilises. Budget for this. The time spent on schema design saves multiples of that time in annotation rework.
Step 3: Source and curate your raw footage
Not all match footage trains equally. The footage you select determines what scenarios your model sees during training, which determines which scenarios it can handle at inference time.
Represent the hard scenarios explicitly. A model trained only on clean, well-lit footage from prime broadcast angles will fail on lower-quality cameras, different lighting conditions and unusual angles. If your production system runs on tactical cameras mounted at the end of the stand rather than the broadcast camera, your training footage needs to include tactical camera footage.
Distribute across conditions. Training footage should cover:
- Multiple camera angles and heights
- Different lighting conditions (afternoon, floodlit, overcast)
- Different stadium and crowd backgrounds
- Different match phases (open play, set pieces, transitions, dead ball situations)
- Multiple teams and kits (similar kit colours create the hardest player ID scenarios)
- Different skill levels if the model will be deployed across levels
Include the edge cases deliberately. A model will encounter its hardest scenarios in production regardless of whether those scenarios appeared in training. Occlusion during corners, ball blur during fast passes, crowded penalty areas, camera cuts during key events — these should be over-represented in training relative to their natural frequency, because they are the scenarios most likely to cause production failures.
Volume benchmarks by model type. There are no universal rules, but as reference points:
- A player detection model for a single sport typically needs thousands of labeled frames across varied conditions to generalise reliably
- A player tracking model needs labeled sequences across full match segments, not just individual frames — the sequence length matters as much as the frame count
- A full event recognition model covering a complete taxonomy for a professional sport is typically trained on data spanning hundreds of matches
- A pose estimation model focused on a specific biomechanical use case may need fewer matches but higher keypoint density per frame
Step 4: Annotate with sport-aware annotators
This is where most teams underestimate the task.
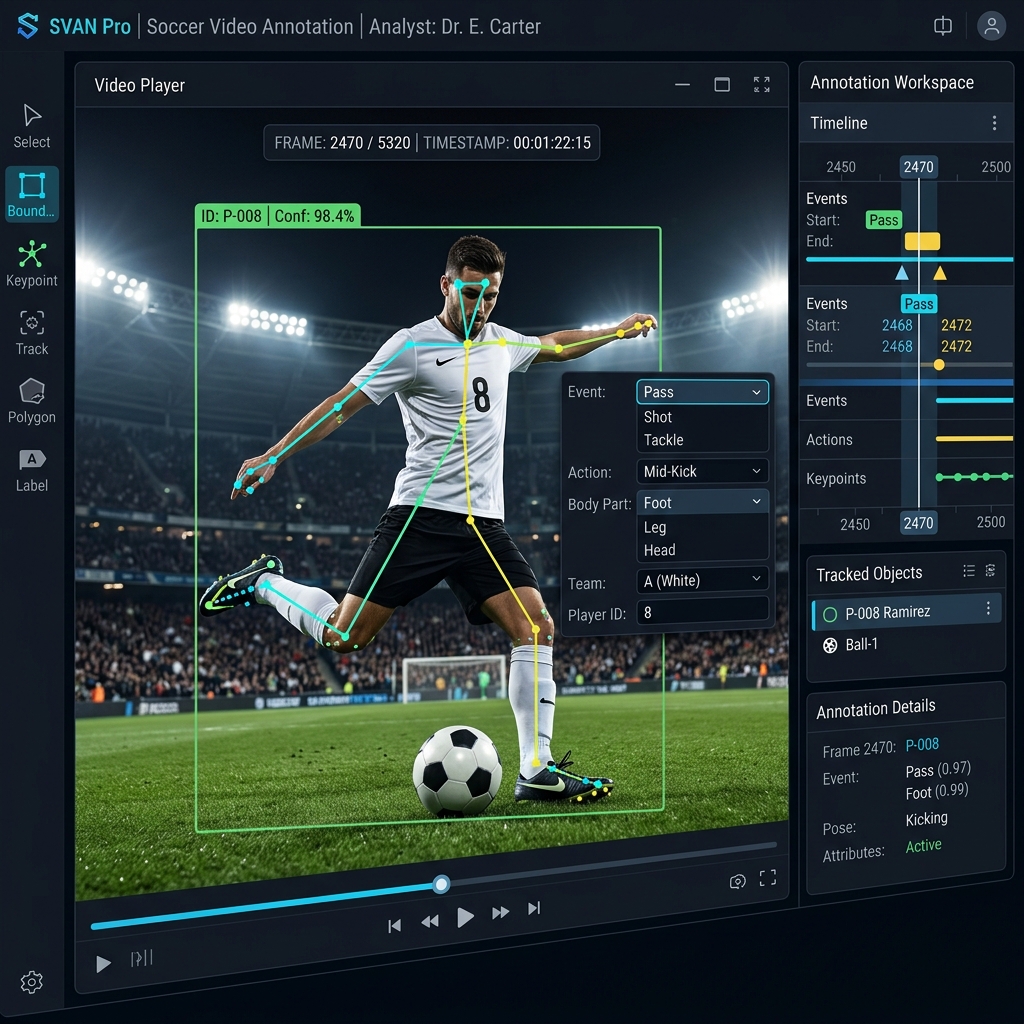 Professional sports annotation interface mapping body keypoints, events, and player tracking details.
Professional sports annotation interface mapping body keypoints, events, and player tracking details.
Annotation tooling — CVAT, Supervisely, Labelbox, Encord and others — provides the interface for drawing boxes, placing keypoints and tagging events. The tool does not provide sport knowledge. The tool does not know that the player who stepped forward before the cross was making a press trigger run, not a forward pass movement. The tool does not know that the ball disappeared behind the net post rather than going out of play. The tool does not know that the contact between two players was a legal shoulder challenge, not a foul.
Sport knowledge comes from the annotator. For sports CV datasets, the annotation workforce must include people who genuinely understand the sport at a level that allows them to make correct event judgments — not just people who can operate annotation software.
The practical implication: for every sport you annotate, the annotation team needs:
- Sport-specific training on the taxonomy before production begins
- Calibration rounds where a small batch is annotated by all team members and differences are reviewed and resolved
- Senior reviewers who understand both the sport and the ML use case
- Documented edge case decisions that are updated when new scenarios emerge and distributed to all annotators
The alternative — using a general-purpose annotation workforce trained only on the schema document — produces datasets that look complete on delivery but contain systematic errors in exactly the scenarios that matter most to the model.
Step 5: QA at the frame level and the sequence level
Quality assurance in sports CV must operate at two distinct levels, and most annotation projects only implement one.
Frame-level QA checks visual accuracy: are bounding boxes tight? Are keypoints placed on the correct body landmarks? Are event labels applied to the correct frame? Are class labels correct? This type of QA catches individual annotation errors and is necessary.
Sequence-level QA checks temporal consistency: does the same player keep the same ID for 500 consecutive frames? Does an event labeled as starting at frame 1,042 actually begin at 1,042, or did the annotator use a different definition of "event start" than the schema specifies? Does the ball trajectory through an occluded sequence make physical sense? Does a labeled pick-and-roll correctly capture the screener setting the pick, the contact, and the separation — or does it only capture the ball handler's movement?
Sequence-level errors are invisible at the frame level. They only appear when you review the data as a temporal sequence — which is also how the model sees it at training time. A player whose ID switches at frame 743 because of an occlusion looks fine in any individual frame before and after frame 743. The switch is only detectable if you trace the ID across the sequence.
QA should also include domain verification: reviewing not just whether labels are visually or temporally correct, but whether they are correct within the rules and context of the sport. This requires QA reviewers who understand the sport, not just annotation review tools.
Step 6: Deliver in the format your training pipeline accepts
A fully annotated, QA-verified dataset is useless if your engineering team cannot ingest it. Delivery format should be defined before annotation begins, not determined at the end.
Common delivery formats for sports CV datasets:
- COCO JSON: standard for detection and segmentation tasks; supports multiple annotation types in a single file structure
- YOLO format: common for object detection training; labels stored as normalised bounding box coordinates in per-frame text files
- CSV or JSON event logs: for event recognition tasks; rows contain event type, start frame, end frame, player IDs and attributes
- Custom JSON schema: for proprietary pipelines; structure defined by the engineering team's training system
- Train / val / test splits: most training pipelines require footage pre-split; the split strategy should be defined before annotation (splitting after annotation is possible but risks data leakage if the same match appears in multiple splits)
Agree the format with your ML team during the schema design phase. Test it with a small pilot batch before full production. A format issue discovered after 100,000 frames are annotated creates significant rework.
Build in-house or partner?
Most teams face this question. The honest assessment:
Build in-house when:
- You annotate a small, stable volume with a fixed schema
- Your team has genuine sport expertise and annotation workflow experience
- Your annotation needs are unlikely to scale significantly
- Security requirements make external access to footage impractical
Partner when:
- Annotation volume is spiky or growing
- You need sport-specific expertise your team doesn't have
- Your engineering team's time is more valuable than the annotation cost
- You need QA processes you don't currently have
- Time-to-data is a bottleneck on your model development cycle
The most common mistake is underestimating the operational overhead of in-house annotation. Building and maintaining a sport-trained annotation team, designing and evolving schemas, running QA processes and managing delivery formats is a full operation — not a part-time task for engineers or analysts.
The six most common mistakes that break sports CV datasets
1. Starting annotation without a documented schema. Annotators fill in schema gaps with their own judgment. Different annotators fill them in differently. The result is inconsistency that accumulates across the entire dataset.
2. Using generic annotators for sport-specific tasks. A correctly placed bounding box on the wrong event is worse than a missing label — it actively mislabels ground truth. Sport knowledge is a prerequisite, not a differentiator.
3. Checking frame quality but not sequence quality. Player ID drift through occlusion and event boundary inconsistency are invisible at the frame level and critical at the sequence level.
4. Annotating all footage at equal priority. Easy footage is not proportionally valuable. The model needs to learn from the hard scenarios: occlusion, fast motion, crowded scenes, ambiguous events. These should be over-represented in the training split.
5. Defining delivery format after annotation. Format mismatches discovered post-delivery create rework that is expensive and sometimes structurally difficult. Agree format first, test it on a pilot batch, then scale.
6. Skipping the pilot. A pilot annotation of 30 to 60 minutes of representative footage — including hard scenarios — reveals schema gaps, annotator calibration issues and QA process weaknesses before they propagate across the full dataset. It is the highest-leverage investment in the project.
Frequently asked questions
What is a sports computer vision training dataset? A sports computer vision training dataset is annotated sports footage that a machine learning model learns from. Annotations describe what is in the footage — where players and the ball are, who each player is across frames, what events are occurring and when — in a structured format the model can train on. The quality of the dataset sets the ceiling on what the model can learn.
How much training data does a sports CV model need? It depends on the model type, the sport and the performance threshold required. Detection models typically need thousands of labeled frames across varied conditions. Tracking models need labeled sequences spanning full match segments. Event recognition models for complete taxonomies are typically trained on data from hundreds of matches. Start with the minimum needed to reach a useful performance threshold, then scale based on where the model fails in evaluation.
What is an annotation schema in sports AI? An annotation schema is the complete specification of what gets labeled, how it gets labeled, what edge cases mean and what format the output takes. It defines every label class, every attribute, every temporal rule and every ambiguous scenario decision before annotation begins. Without a schema, different annotators make different decisions on the same footage, producing noise that limits model accuracy regardless of volume.
How do you handle occlusion in sports video annotation? Occlusion — when a player, ball or object is partially or fully hidden — must be explicitly addressed in the annotation schema. Standard approaches include: an occlusion flag on each label indicating partial or full visibility; a rule for whether to label the predicted position or leave the frame unlabeled; and a player re-identification protocol defining how the annotator confirms identity when the object reappears. Models trained on data without clear occlusion handling learn to drop identity at the moment the sport becomes hardest to read.
What annotation format is best for sports CV training? It depends on the model architecture and training pipeline. COCO JSON is the most common format for detection and segmentation. YOLO format works well for detection-only models. Event recognition datasets typically use CSV or JSON event logs with frame references. The most important principle is to agree format with the engineering team before annotation begins and validate it with a pilot batch.
What is the difference between frame-level QA and sequence-level QA? Frame-level QA checks whether individual annotations are visually accurate — boxes are tight, keypoints are placed correctly, event labels are on the right frame. Sequence-level QA checks whether annotations are consistent across time — player IDs remain stable through occlusion, event boundaries are defined consistently, ball trajectories make physical sense through gaps. Both are necessary. Sports CV models train on sequences, not individual frames, so sequence-level errors are directly reflected in model performance.
Should I build an annotation team in-house or use a specialist partner? Building in-house makes sense when volume is small and stable, your team has sport expertise and the operational overhead is manageable. Using a specialist partner makes sense when volume is growing, your team lacks sport knowledge, or annotation is creating a bottleneck on model development. The most common mistake is underestimating how much operational infrastructure annotation requires — schema governance, annotator training, calibration, QA and delivery management — and treating it as a task that can run alongside engineering without dedicated resource.
How long does it take to build a sports CV training dataset? It depends on volume, complexity and the maturity of the annotation process. Schema design for a new sport or model type typically takes two to four weeks before annotation begins. A pilot batch of representative footage takes one to two weeks to annotate and review. Full production annotation rate depends on label density — event logs annotate faster than skeletal keypoints, which annotate faster than dense segmentation masks. A realistic timeline for a first production-quality dataset is two to four months from schema design to delivery, including QA cycles.
What footage is best for sports CV model training? Footage that represents the scenarios the model will encounter in production — including the hard ones. Prioritise: multiple camera angles and heights, varied lighting and stadium backgrounds, crowded and occluded scenes, multiple teams and kit colour combinations, and all relevant match phases including set pieces, transitions and dead ball situations. Easy footage is not proportionally valuable; the model needs to learn from the scenarios where it is most likely to fail.
The takeaway
A sports computer vision model is only as good as the dataset it was trained on. The six steps — define the objective, design the schema, curate the footage, annotate with sport knowledge, QA at frame and sequence level, deliver in the right format — are where model performance is determined. Architecture and training technique matter; they matter less than the data.
If you are building a sports CV dataset and need a partner for annotation, schema design, QA or delivery — see how Train Matricx works or review annotated dataset results in our case studies. We annotate a free pilot clip to your production standard so you can evaluate quality before committing to any volume.
Written by
Train Matricx Team

