
The Plateau of Algorithmic Tracking
If you run an AI Research Lab focused on Sports Computer Vision in 2026, you already know the dirty secret of the industry: Getting a tracking model to 90% accuracy is easy. Solving the last 10% is agonizing.
When deploying a YOLOv8 or advanced transformer-based tracker, the initial results are often spectacular. The model successfully tracks a lone tennis player or a striker running in open space. However, as the algorithmic complexity scales, researchers inevitably hit a severe plateau.
The models begin to hallucinate under pressure. They drop player IDs during a basketball pick-and-roll, they confuse a hockey stick for a skate, and they entirely lose temporal consistency during a massive football tackle.
 Elite AI Labs require enterprise-grade data infrastructure to break through the 90% accuracy plateau.
Elite AI Labs require enterprise-grade data infrastructure to break through the 90% accuracy plateau.
Why Automated Labeling Fails the "Edge Case" Test
Modern AI Labs often attempt to bypass manual annotation by utilizing "Auto-Labeling" scripts or pre-trained baseline models. While this technique accelerates initial prototyping, it introduces fatal structural flaws into the final dataset.
Auto-labelers fail catastrophically during Edge Cases. In sports AI, an edge case isn't a rare anomaly - it happens dozens of times per match.
The Nightmare of Deep Occlusion
Consider a rugby scrum or an ice hockey battle against the boards. You have multiple players, wearing similar high-contrast jerseys, physically tangling limbs. To a computer vision algorithm, this is a mess of overlapping pixels with no distinct semantic boundaries.
When an auto-labeler attempts to process deep occlusion, it inherently guesses. It merges bounding boxes, snaps keypoints to the wrong player's skeleton, and poisons your Ground Truth dataset with algorithmic bias.
 Extreme occlusion - like a hockey board battle or rugby scrum - breaks automated tracking and requires human intervention.
Extreme occlusion - like a hockey board battle or rugby scrum - breaks automated tracking and requires human intervention.
The Human-in-the-Loop (HITL) Solution
To achieve the 99.9% precision demanded by top-tier broadcasters and tactical coaching software, leading AI Labs are fundamentally shifting their architecture. They are abandoning pure automation and crowdsourcing, adopting instead highly managed Human-in-the-Loop (HITL) pipelines.
How HITL Orchestration Works
- Algorithmic Inference: The AI Lab's proprietary model scans the RAW sports footage, generating bounding boxes and 33-point skeletal keypoints.
- Confidence Thresholding: The system flags any frame where the model's confidence rating drops below 95% (e.g., during a massive collision or motion blur event).
- Expert Intervention: These specific, highly complex "Edge Case" frames are immediately routed to a managed team of expert human annotators.
- Correction and Re-injection: The human experts manually correct the temporal drift, redraw the occluded keypoints based on anatomical intuition, and feed the pristine Ground Truth data back into the neural network for active learning.
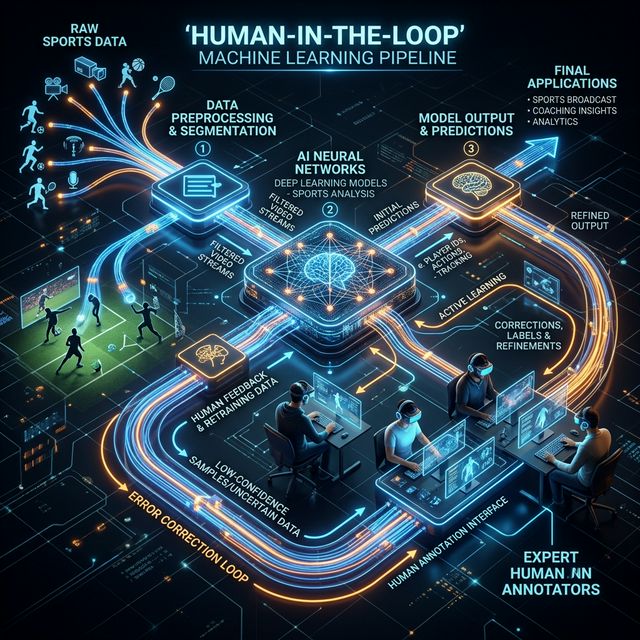 A structured HITL pipeline ensures that predictive neural networks learn from pristine, human-verified edge cases.
A structured HITL pipeline ensures that predictive neural networks learn from pristine, human-verified edge cases.
Why AI Labs Outsource the "Human" Layer
Building an ML model requires elite Data Scientists. Managing a specialized workforce of 500+ human annotators requires an entirely different operational skillset.
When AI Labs attempt to manage annotation internally, they burn hundreds of thousands of dollars on operational overhead. When they rely on cheap crowdsourcing (like Mechanical Turk), they receive catastrophic data quality because the gig-workers do not understand offside rules, biomechanics, or complex ontology trees.
Partnering with Train Matricx
This is the operational gap that Train Matricx fills for global AI Labs.
We provide the dedicated "Human Engine" for your HITL pipeline. We don't just supply standard labelers; we provide domain-expert teams trained specifically in the physics and rules of athletic competition.
If your model flags a complex 15-frame occlusion event during a Premier League match, our team steps in, utilizes our sub-pixel temporal interpolation tools, and resolves the ID drift flawlessly. We integrate directly into your exact tooling ecosystem (whether you use CVAT, Encord, Supervisely, or a proprietary platform).
Stop letting edge cases ruin your model's accuracy.
Deploying a world-class model requires world-class data. Book a Free Consultation with Train Matricx today and learn how our managed workforce can accelerate your AI pipeline.
Written by
Asif Ikbal

